
We try to analyse bibliographical data using big data technology (flink, elasticsearch, metafacture).
Here a first sketch of what we're aiming at:
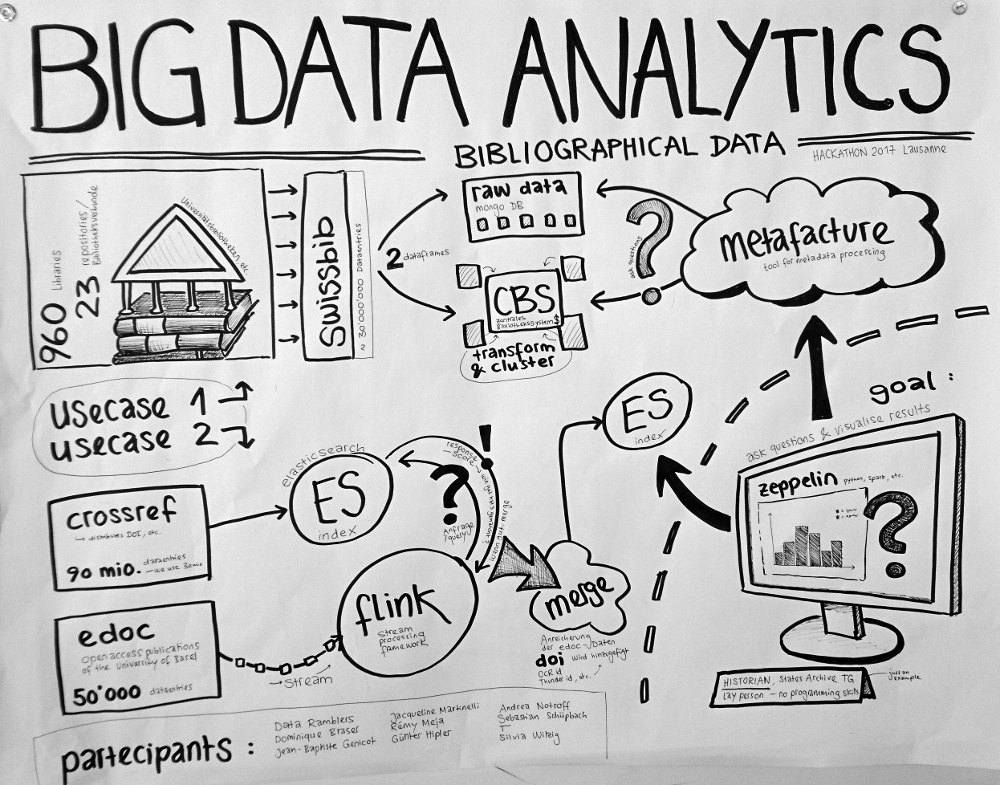
Datasets
We use bibliographical metadata:
Swissbib bibliographical data https://www.swissbib.ch/
-
Catalog of all the Swiss University Libraries, the Swiss National Library, etc.
-
960 Libraries / 23 repositories (Bibliotheksverbunde)
-
ca. 30 Mio records
-
MARC21 XML Format
-
→ raw data stored in Mongo DB
-
→ transformed and clustered data stored in CBS (central library system)
-
Institutional Repository der Universität Basel (Dokumentenserver, Open Access Publications)
-
ca. 50'000 records
-
JSON File
crossref https://www.crossref.org/
-
Digital Object Identifier (DOI) Registration Agency
-
ca. 90 Mio records (we only use 30 Mio)
-
JSON scraped from API
Use Cases
Swissbib
Librarian:
- For prioritizing which of our holdings should be digitized most urgently, I want to know which of our holdings are nowhere else to be found.
- We would like to have a list of all the DVDs in swissbib.
- What is special about the holdings of some library/institution? Profile?
Data analyst:
- I want to get to know better my data. And be faster.
→ e.g. I want to know which records don‘t have any entry for ‚year of publication‘. I want to analyze, if these records should be sent through the merging process of CBS. Therefore I also want to know, if these records contain other ‚relevant‘ fields, defined by CBS (e.g. ISBN, etc.). To analyze the results, a visualization tool might be useful.
edoc
Goal: Enrichment. I want to add missing identifiers (e.g. DOIs, ORCID, funder IDs) to the edoc dataset.
→ Match the two datasets by author and title
→ Quality of the matches? (score)
Tools
elasticsearch https://www.elastic.co/de/
JAVA based search engine, results exported in JSON
Flink https://flink.apache.org/
open-source stream processing framework
Metafacture https://culturegraph.github.io/,
https://github.com/dataramblers/hackathon17/wiki#metafacture
Tool suite for metadata-processing and transformation
Zeppelin https://zeppelin.apache.org/
Visualisation of the results
How to get there
Usecase 1: Swissbib
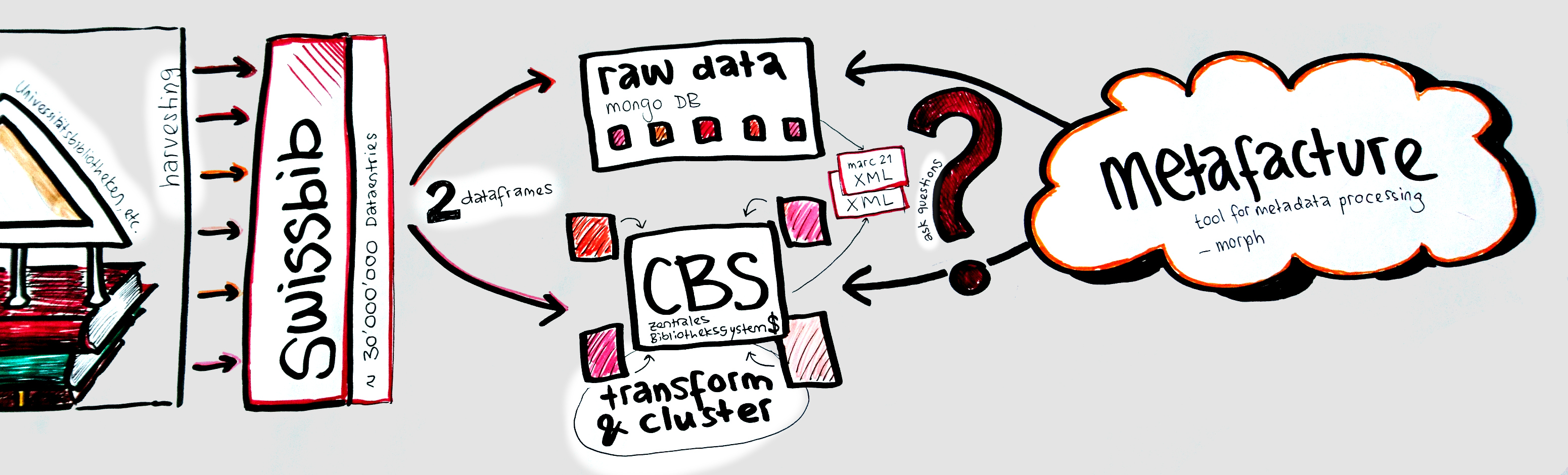
Usecase 2: edoc
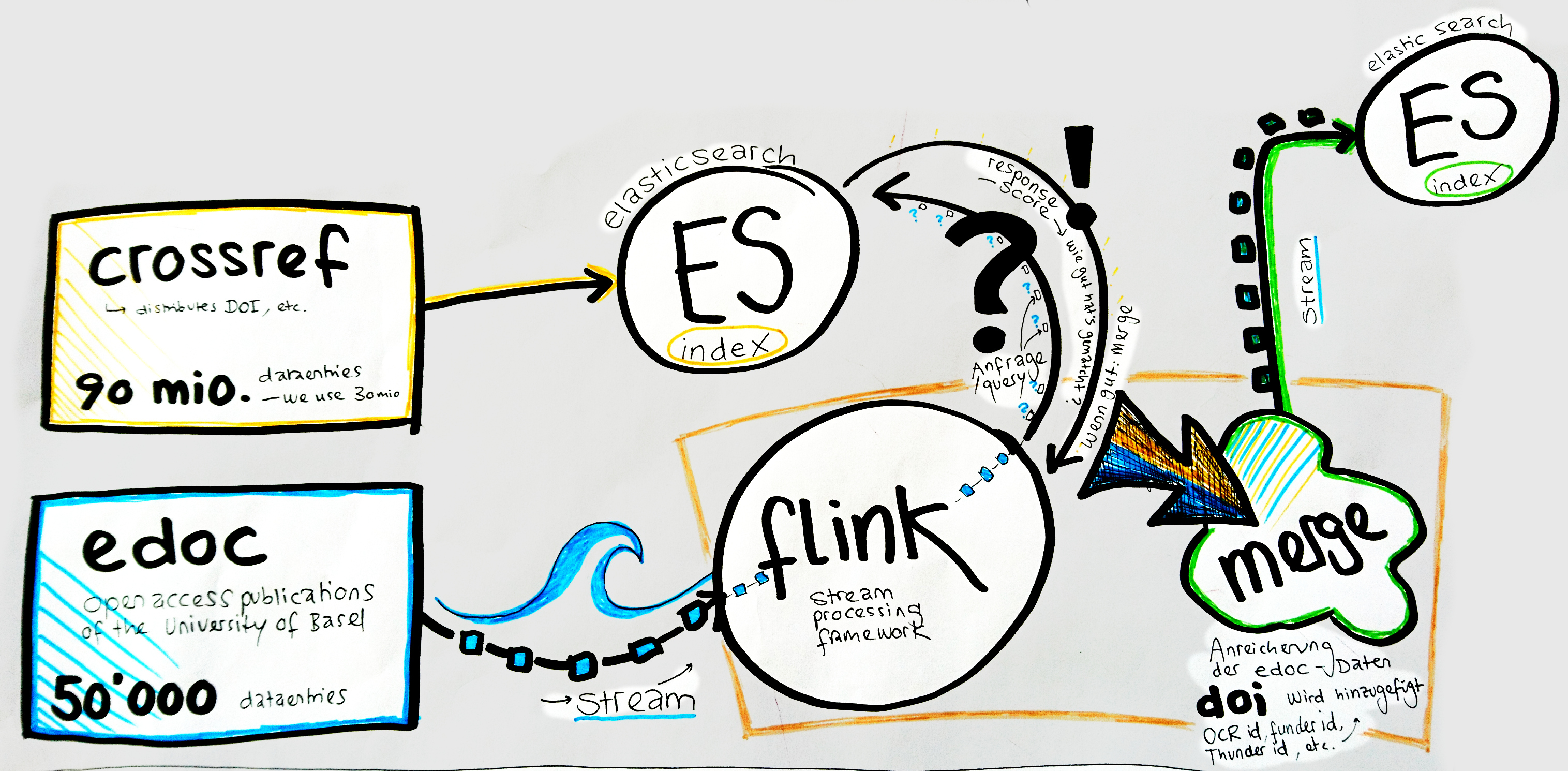
Links
Data Ramblers Project Wiki https://github.com/dataramblers/hackathon17/wiki
Team
-
Data Ramblers https://github.com/dataramblers
-
Dominique Blaser
-
Jean-Baptiste Genicot
-
Günter Hipler
-
Jacqueline Martinelli
-
Rémy Meja
-
Andrea Notroff
-
Sebastian Schüpbach
-
T
-
Silvia Witzig